
Hiring teams keep “testing communication” by asking vague interview questions and then acting surprised when the hire cannot write a usable handoff, clarify requirements, or de-escalate a messy cross-team situation.
A real communication test design does three things:
- It mirrors the communication tasks the job actually requires.
- It scores responses with a rubric, not vibes.
- It predicts outcomes you care about (quality, speed, rework, escalations).
Table of Contents
- Communication Test Design: What It Should Measure and What It Should Predict
- Start with job analysis (global, US-leaning)
- Build the test blueprint
- Write items and score them consistently
- Validate and protect fairness
- Implement in the hiring workflow (and where OAD fits)
Communication Test Design: What It Should Measure and What It Should Predict
Communication is not a personality trait. It is job behavior expressed through a channel: written updates, ticket notes, customer messages, status reports, handoffs, meeting decisions, escalation summaries.
When designing a communication test, it is essential to clearly define its purpose and ensure it aligns with your organizational goals, such as supporting leadership, reinforcing values, or contributing to a positive workplace culture.
If your assessment does not specify the channel and the context, you are not measuring job communication. You are measuring English fluency, confidence, or interview polish.
Developing a communication test involves a structured process that uses both quantitative and qualitative methods to measure outcomes, ensuring the test is effective and relevant to your organization’s needs.
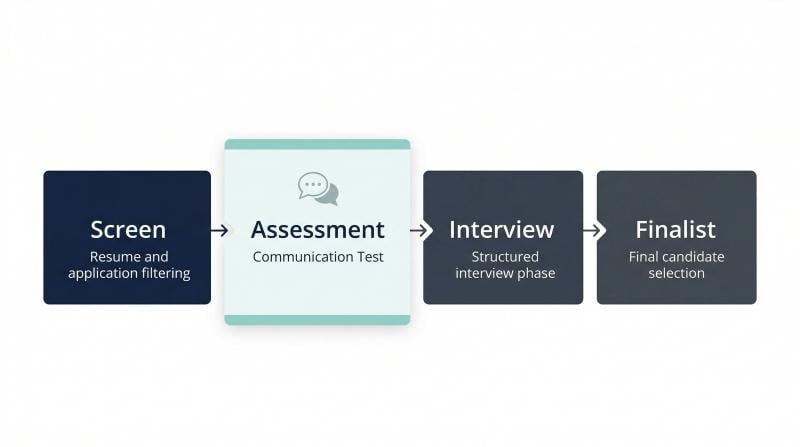
Define the hiring stage and decision it supports
Start by choosing where the test sits in the funnel, because that determines how complex it should be; for many teams, adding a fast, validated pre-screen like the OAD personality survey to reveal fit before interviews can sharpen early decisions.
- Early screen (high volume): short, highly structured, low-rater-effort. Goal: remove clear mismatches without filtering out capable candidates who do not interview well.
- Mid-funnel (skills confirmation): a scenario-based test plus a short writing task. Goal: confirm the person can do the work communication.
- Finalist (risk control): deeper simulation or role-play where miscommunication is expensive. Goal: reduce false positives before offer.
Design rule: the earlier the stage, the shorter and more standardized the test needs to be. Longer tests are not “more predictive” if they introduce fatigue, inconsistent scoring, or lower completion rates.
Turn “communication” into observable behaviors
Stop using abstract labels like “strong communicator.” Replace them with behaviors that can be seen in work output.
Examples you can actually score:
- Clarity: states the point early, uses concrete terms, removes ambiguity
- Structure: uses headings, bullets, and logical sequencing when appropriate
- Accuracy: reflects constraints, details, and dependencies correctly
- Audience fit: adjusts tone and detail level for peer, manager, customer, or cross-functional partner
- Action orientation: defines next steps, owners, timelines, and decision points
- Risk handling: flags uncertainty, asks the right clarifying questions, documents assumptions
For global hiring: separate “language mechanics” from “communication quality.” Candidates can communicate well with minor grammar issues. Your rubric should score the job outcome: can someone understand, act, and avoid errors.
What it should predict is also practical. Pick outcomes you can observe after hire:
- fewer handoff errors and clarifications
- lower rework caused by misunderstandings
- faster cycle time from request to resolution
- cleaner documentation that others can use
- fewer escalations driven by unclear updates
If you cannot name the outcome you want to predict, you do not have a test. You have content.
Start with job analysis (global, US-leaning)
If you skip job analysis, your communication test will measure whatever the test writer personally finds “good.” That is how you end up filtering for corporate-sounding candidates instead of effective ones, and why you still see teams leaning on vague interview questions instead of structured strategies to assess communication skills in interviews.
Your job analysis does not need to be a six-month research project. For a ~1k-word implementation guide, the goal is a clean map from real work → test tasks → scoring.

Identify 5–7 critical communication tasks
Pick a small set of tasks that are (a) frequent, (b) high-risk when done poorly, and (c) representative across regions. For most professional roles, especially engineering-adjacent and operations-heavy environments, the same patterns show up globally:
- Async status update: summarize progress, blockers, and next steps in writing
- Handoff message: transfer context to another person or team without losing critical details
- Clarification request: ask the minimum set of questions to unblock work
- Escalation summary: explain impact, urgency, and decision needed without drama
- Customer-facing explanation (internal or external): translate complexity into understandable language
- Incident or defect update: document what happened, what changed, and what is being done
For each task, define the communication channel (ticket, email, Slack/Teams update, meeting notes) and the typical constraint (time pressure, incomplete info, cross-functional tension).
This is where “global with US preference” matters. In many US-based organizations, documentation expectations are shaped by compliance, auditability, and legal defensibility. That pushes you toward clearer written trails: decisions, rationale, and ownership. In other regions, you may see higher reliance on informal coordination, but global teams still need written artifacts for async work. Design the test around that reality.
Define success and failure patterns across regions and teams
Interview 3–6 SMEs across seniority levels and at least two regions if you hire globally. You are not looking for opinions on “good communication.” You are looking for patterns:
Ask for examples of:
- a handoff that went wrong and the cost
- a status update that prevented escalation
- a message that created rework or conflict
- documentation standards that matter in the role
Then extract failure modes you can test for:
- missing constraints and dependencies
- unclear ownership or next step
- wrong level of detail for the audience
- soft language that hides risk (“should be fine”)
- overconfidence with missing facts
- tone that inflames cross-team friction
Those become scoring criteria. Not “professional tone.” Not “seems confident.” Criteria that map to business outcomes and help you evaluate behavioral fit between candidates and specific roles.
Build the test blueprint
A test blueprint is the part most teams skip, then they wonder why the assessment is inconsistent. The blueprint forces discipline: what you test, how you test it, and how you score it.
Choose the right format (SJT + short writing sample is usually enough)
For most roles, a strong minimal combo is:
- Situational Judgment Test (SJT): candidates choose or rank responses to realistic scenarios
- Short writing sample: candidates write a message based on a prompt (handoff, escalation, status update), ideally delivered through a secure, individualized assessment account like OAD’s application access for each employee
Why this works:
- SJT captures judgment and prioritization under constraints.
- Writing sample captures clarity, structure, and actionability in the real channel.
Avoid formats that look “fancy” but add noise:
- unstructured role-plays without standardized prompts
- long essays that reward verbosity
- pure multiple choice grammar tests (easy to game, not job predictive)
Design rule: choose formats that reflect job channels, not generic communication ideals.
Set length, timing, and realistic constraints
Your test should respect candidate time and reduce fatigue effects. For mid-funnel communication assessments, a practical target is:
- 15–25 minutes total, depending on role complexity
- 3–5 SJT scenarios (1–2 minutes each)
- 1 writing task (8–12 minutes)
- optional: 1 clarification task (2–4 minutes) where they ask questions instead of answering
Add constraints that exist in the job:
- limited context
- competing priorities
- an audience with different needs (peer vs manager vs customer)
- a requirement to document assumptions
What you should not add: trick wording, obscure cultural references, or “gotcha” traps. Those test familiarity, not communication ability.
Map each item to an outcome metric
Each scenario should link to a business outcome you actually care about. Example mapping:
- Handoff prompt → predicts handoff errors, rework, ramp time
- Escalation summary → predicts escalation frequency, incident handling quality
- Status update → predicts cycle time, stakeholder satisfaction
- Clarification task → predicts blocker resolution speed, fewer misaligned deliverables
This mapping makes your validation step possible later. If you cannot link an item to an outcome metric, remove it.
Write items and score them consistently
This is where most “communication tests” quietly die. Teams write decent prompts, then score them like a book club: whoever feels strongly wins.
A communication test only predicts job performance if scoring is stable, just as data-driven coaching tools like behavioral insights for executive coaches and leaders depend on consistent, interpretable scores.

Scenario-based prompts that mirror real work
Good prompts are specific, role-realistic, and constrained. They force the candidate to make tradeoffs the job actually demands.
A useful prompt structure:
- Context: what happened, what is known, what is unknown
- Audience: who the message is for
- Goal: what the message needs to achieve
- Constraints: time, risk, dependency, tone requirements
- Output format: ticket update, email, Slack message, meeting summary
Example (writing task style):
“Write a 6–10 sentence status update to a cross-functional channel. The work is blocked by an external dependency. Your manager wants clarity on impact and next steps. Include what you completed, what is blocked, what you need, and by when.”
Notice what is missing: vague instructions like “communicate professionally.”
Global note: keep names, idioms, and culture-bound scenarios out of it. If the role requires region-specific customer communication, test that explicitly as a separate version.
Simple rubrics with anchors (what “good” looks like)
A rubric should make scoring boring. Boring is good.
Use 4–5 dimensions max. More dimensions increases rater noise. For each dimension, define “strong,” “acceptable,” and “weak” with short anchor examples.
A practical rubric set for most roles:
- Clarity and structure
- Strong: lead point first, clean structure, minimal ambiguity
- Weak: buried point, unclear sequencing, hard to act on
- Completeness and accuracy
- Strong: includes constraints, dependencies, correct details
- Weak: missing critical info or invents certainty
- Actionability
- Strong: clear next steps, owner, timeline, decision needed
- Weak: no ownership, no timeline, “FYI” messaging
- Audience alignment and tone
- Strong: right level of detail, neutral tone, de-escalates
- Weak: overly technical for audience, blame tone, vague politeness
- Risk handling (optional but valuable)
- Strong: flags uncertainty, states assumptions, requests clarification well
- Weak: hides risk, overconfident, no clarifying questions
Score each 1–5 with a one-sentence rationale. If raters cannot justify the score in one sentence, the rubric is not tight enough.
Reduce rater noise (calibration or blind scoring where possible)
Open responses are powerful, and they are also where bias sneaks in.
Three controls that actually work:
- Calibration: two raters score 10–20 sample responses together before launch, agree on anchors, then score independently.
- Blind scoring: hide name, school, location, and any demographic signals when feasible.
- Rubric tightening: if raters disagree often, the fix is almost always rubric clarity, not “better raters.”
If you cannot invest in rater training, reduce open-response weight and lean more on structured formats like SJT with standardized scoring.
Validate and protect fairness
You do not need a PhD to be responsible here. You need evidence that the test is (a) consistent, (b) job-related, and (c) not creating avoidable adverse impact.
Reliability basics (consistency across items and raters)
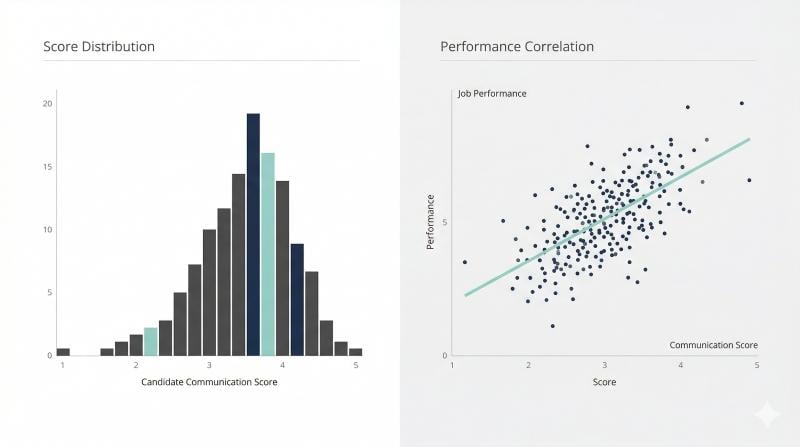
Reliability answers: would the candidate score roughly the same if we measured again?
What to check in practice:
- Do scores spread out, or does everyone cluster in the middle?
- If two raters score the same response, do they land close?
- Do candidates who write clearly in one prompt also do so in another?
If you see wild rater disagreement, your test is not measuring communication. It is measuring rater preference.
Criterion validity (link scores to job outcomes)
This is the “predicts job performance” part. It requires a simple plan, and psychometrically validated tools like the OAD Survey with over 35 years of validation data can strengthen this step:
- Pilot the test with candidates or new hires.
- Track a small set of outcomes over time (quality ratings, rework rate, escalations, ramp time).
- Check whether higher test scores correspond to better outcomes.
Use precise numbers only when sourced and documented. If you cannot support a specific statistic, keep it directional: “higher scores aligned with fewer escalations over the first 90 days,” not “reduced escalations by 37%.”
In US contexts, validation and documentation also support defensibility under common selection standards. Globally, you still want this evidence because it prevents you from scaling a biased or useless test across regions.
Bias checks (non-native speakers, culture-bound scenarios, DIF if available)
Communication assessments commonly disadvantage candidates when they ignore what actually drives behavior; understanding internal motivators and behavioral needs that shape communication helps you design fairer scoring.
- non-native speakers (especially when grammar is overweighted)
- candidates unfamiliar with your internal jargon
- cultures with different norms around directness and hierarchy
Controls that preserve job relevance:
- score job effectiveness over perfect English, unless the role explicitly requires it
- remove idioms, sarcasm, and culture-bound cues from prompts
- separate “language proficiency” from “communication structure” in scoring
- review subgroup score patterns and investigate large gaps
If you have enough data and expertise, you can run item-level fairness checks (like DIF). If you do not, you can still do the practical version: audit prompts and rubrics for culture traps, then validate outcomes across groups, watching for early risk and readiness signals such as burnout or disengagement.

Implement in the hiring workflow (and where OAD fits)
A strong communication test should reduce interview time, not add ceremony.
Where it sits in the funnel and what it replaces
Common high-signal placement:
- after resume screen, before deep interviews
- used to replace “tell me about a time you communicated well” interviews
- used to focus interviews on work review: “walk us through your choices”
Implementation rule: if the test does not change what interviewers do, it will be ignored. Make it actionable:
- define score bands (e.g., advance, review, do-not-advance)
- require a short rater note explaining the score
- train interviewers to use results as evidence, not as a label
How OAD complements the test
Communication output is behavior in context. OAD adds a different layer: stable behavioral patterns that shape how someone tends to communicate under pressure, in ambiguity, and in conflict.
Used together, especially for founders and senior leaders who need to scale hiring decisions, as described in OAD’s approach to building leadership teams with long-term role fit in mind:
- the communication test shows whether the candidate can execute key tasks
- OAD helps predict consistency, collaboration style, and fit with role demands, which matters even more in high-stakes contexts like private equity portfolio hiring and integration or when you are building and promoting within high-performing sales teams
